
因为一个一个的去查实在太慢了。为了解决这个问题。我的工具出现了。
下面先贴上效果图
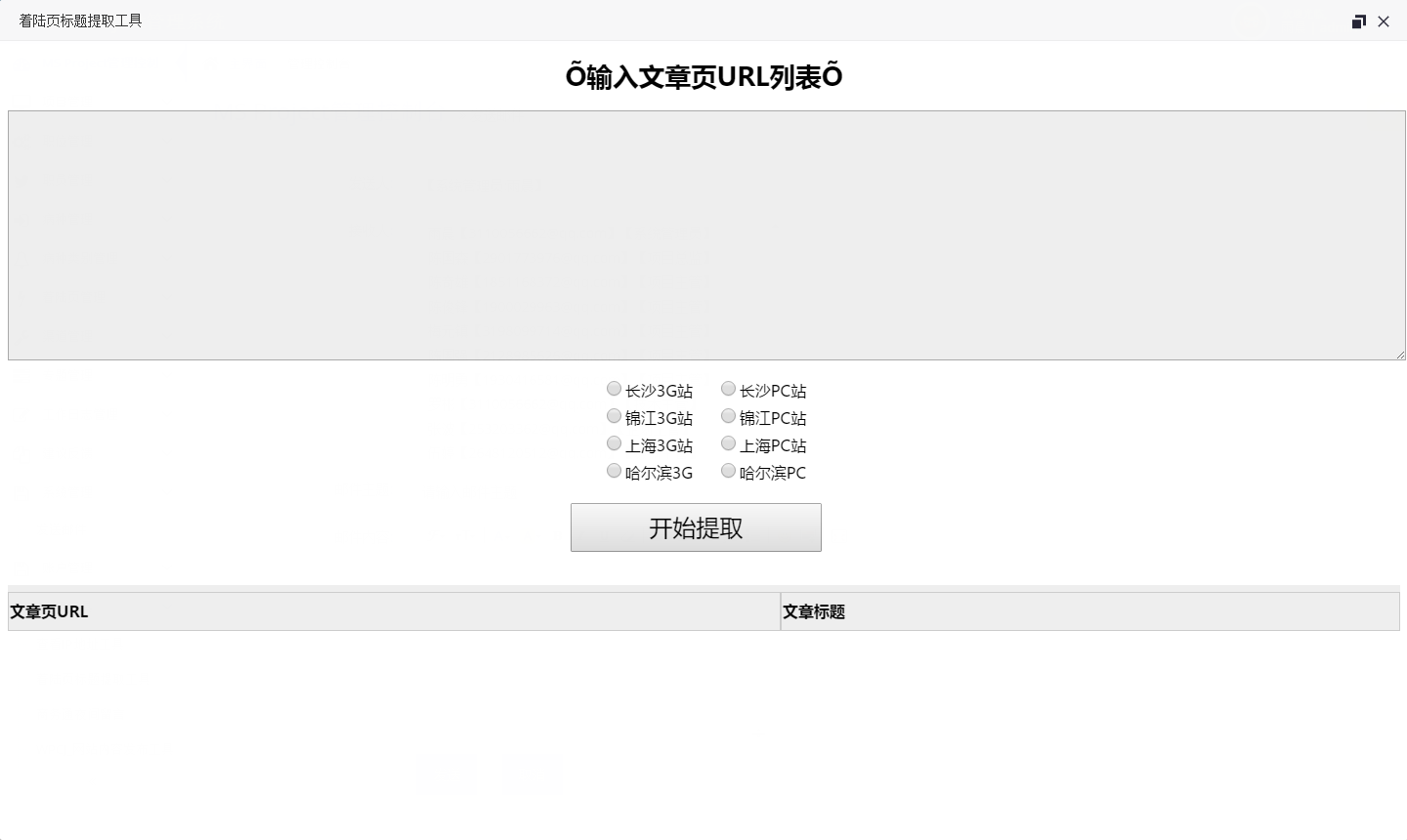
只需填写着陆页文章URL路径列表。即可生成标题列表。
下面贴出ASP服务器脚本
解析脚本:
function bs2str(bs,ch){
var re='';
with(new ActiveXObject("adodb.stream")){
type = 1,open(),Write(bs);
Position = 0,Type = 2;
Charset=ch,re=ReadText();
Close()
}
return re;
}
|
正则匹配:
var titReg=/[^>]+(?=<\/title)/i;
titReg=/<div class="art_conenttitle">([\s\S]*?)<\/div>/i; //默认不选的情况下为长沙3g.kzdz120.com手机站
var kwReg=/<meta.+?name\s*=\s*['"]?(keywords|description)\b.+?content\s*=\s*(['"])([^\2]+?)\2/ig;
var chReg=/Charset=([^;]+)/i;
function getInfo(url,radio_val){
var xh = new ActiveXObject("Microsoft.XMLHttp"),ch,text,re={},ms;
//try {
with(xh) open("GET", url, false),send();
ch=chReg.test(xh.getResponseHeader("Content-Type"))?RegExp.$1:'utf-8';
text=/utf-8/i.test(ch)? bs2str(xh.responseBody,ch):xh.responseText;
if (radio_val == "cs_3g") //长沙3G站
{
if (url.indexOf("wap.tyek120.com")!=-1) {
titReg=/<h2 class="art_tit">([\s\S]*?)<br\/>/i;
}else if (url.indexOf("3g.kzdz120.com")!=-1){
titReg=/<div class="art_conenttitle">([\s\S]*?)<\/div>/i;
titReg=/<h2 style="line-height: 44px;" >([\s\S]*?)<\/h2>/i;
}else if (url.indexOf("3g.kcbz120.com")!=-1){
titReg=/<div class="art_conenttitle">([\s\S]*?)<\/div>/i;
}
re.title=text.match(titReg);
}
else if (radio_val == "cs_pc") //长沙PC站
{
if (url.indexOf("www.kzdz120.com")!=-1 || url.indexOf("www.tyek120.com")!=-1)
{
titReg=/<h3>([\s\S]*?)<\/h3>/i;
}else if (url.indexOf("www.kcbz120.com")!=-1)
{
titReg=/<h1>([\s\S]*?)<\/h1>/i;
}
re.title=text.match(titReg);
}
else if(radio_val == "jj_pc") //锦江PC站
{
if (url.indexOf("www.jj2ek.com")!=-1)
{
titReg=/<span style="width: 100%;color: #158064; font-size: 26px;"><b>([\s\S]*?)<\/b><\/span>/i;
}else if (url.indexOf("dd.jj2120.com")!=-1)
{
titReg=/<h4>([\s\S]*?)<\/h4>/i;
}
re.title=text.match(titReg);
}
else if(radio_val == "jj_3g") //锦江3G站
{
if (url.indexOf("3g.jj2ek.com")!=-1)
{
titReg=/<p style="float: left; width:100%;font-size: 20px;"><b>([\s\S]*?)<\/b>/i;
titReg=/<h1 class="wH1">([\s\S]*?)<\/h1>/i;
}else if (url.indexOf("8g.jj2ek.com")!=-1 || url.indexOf("5g.jj2120.com")!=-1)
{
titReg=/<h3>([\s\S]*?)<\/h3>/i;
}
re.title=text.match(titReg);
}
else if(radio_val == "heb_3g") //哈尔滨3G站
{
if (url.indexOf("3g.hebdyyy.org.cn")!=-1 || url.indexOf("3g.hebsdyyyek.org.cn")!=-1 || url.indexOf("3g.hebsdyyy120.org.cn")!=-1 || url.indexOf("3g.dyyyek.org.cn")!=-1 || url.indexOf("3g.hebek120.org.cn")!=-1)
{
titReg=/<h2 class="art_tit">([\s\S]*?)<br\/>/i;
}
re.title=text.match(titReg);
}
else if(radio_val == "heb_pc") //哈尔滨PC站
{
if (url.indexOf("www.hebek120.org.cn")!=-1 || url.indexOf("www.dyyyek.org.cn")!=-1 || url.indexOf("www.hebsdyyy120.org.cn")!=-1 || url.indexOf("www.hebsdyyyek.org.cn")!=-1 || url.indexOf("www.hebdyyy.org.cn")!=-1)
{
titReg=/<div class="arc_cont">([\s\S]*?)<h3>/i;
titReg=/<div class="article_left1Main">([\s\S]*?)<h2><span>/i;
titReg=/<div class="art_title">([\s\S]*?)<\/div>/i;
}
//else if (url.indexOf("www.hljek120.com")!=-1 || url.indexOf("www.hebek120.com")!=-1)
//{
//titReg=/<div class="article_left1Main">([\s\S]*?)<h2><span>/i;
//}
re.title=text.match(titReg);
}
else
{
re.title=text.match(titReg);
}
while (ms = kwReg.exec(text))re[ms[1].toLowerCase()]=ms[3];
for(var k in re)re[k]=re[k]||'';
re.html=text
return re;
}
|
以上脚本需要运行在服务器端。须被包含在代码块<script language="jscript" runat="server"></script>里面。
如果有需要源码的朋友也可以联系我。
注:本文内容均系原创。如需转载分享请标明出处。
注:本文内容均系原创。如需转载分享请标明出处。