
于是乎我搜索了一个我喜欢的歌手的所有音乐。找到了365音乐网站。但是打开发现只能在线听。还是没有可以下载的通道。
我以《等一分钟》为例子,打开页面。然后上F12,打开查看源码(红色标注处是关于因为相关信息。有可能是音乐ID)
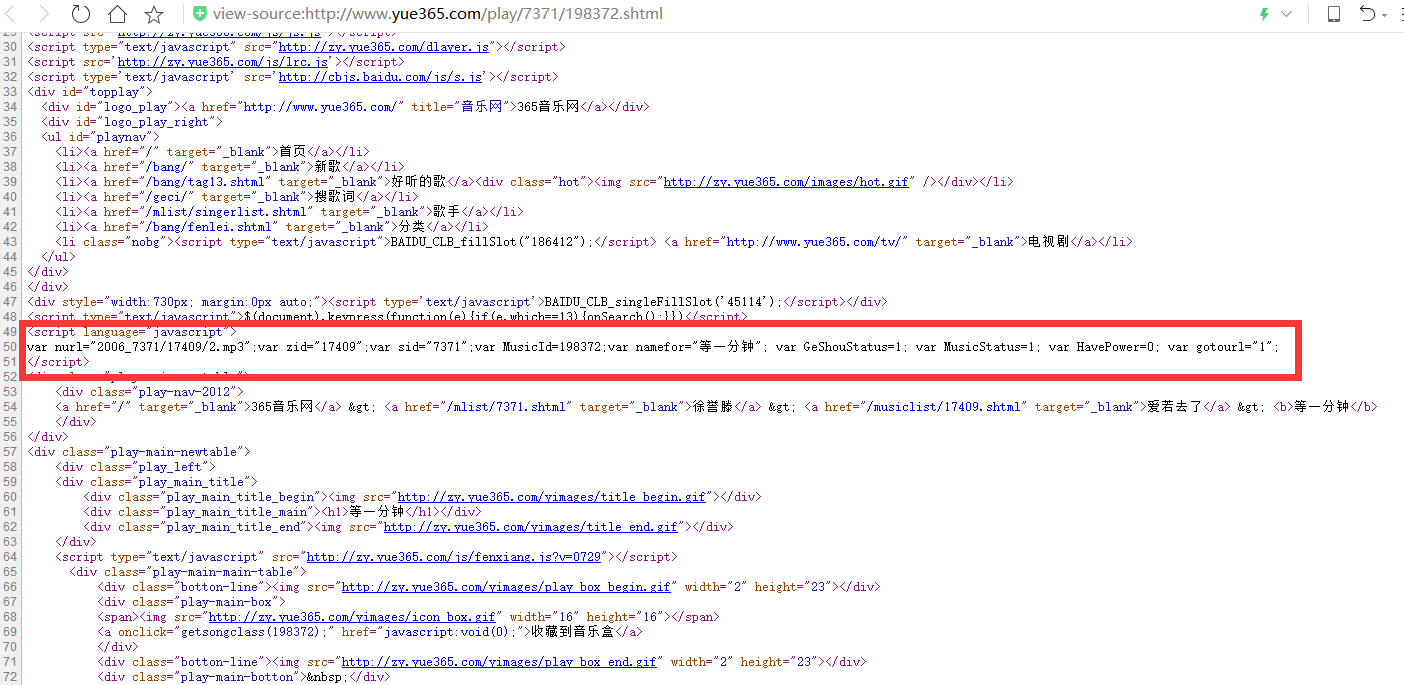
然后我们查找处理音乐URL相关的JS文件,找到下图红色标注处JS文档
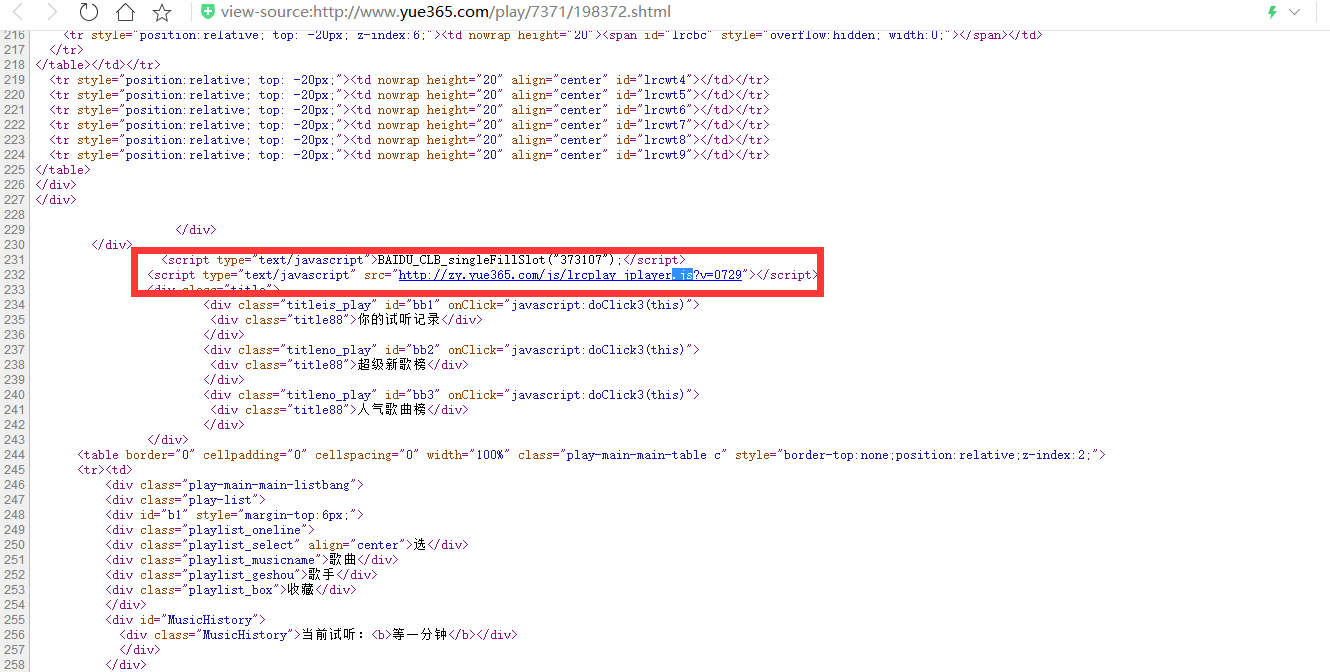
打开JS文档。找到下图红色标注处。这个地方就是来处理真实音乐地址的地方。我们发现了相应的规律。
发现音乐存放在一个另一个URL服务器上的。分两级目录。第一级目录是音乐ID除以30000然后取整,第二级目录是音乐id除以2000然后取整。最后构造真实音乐url路径。
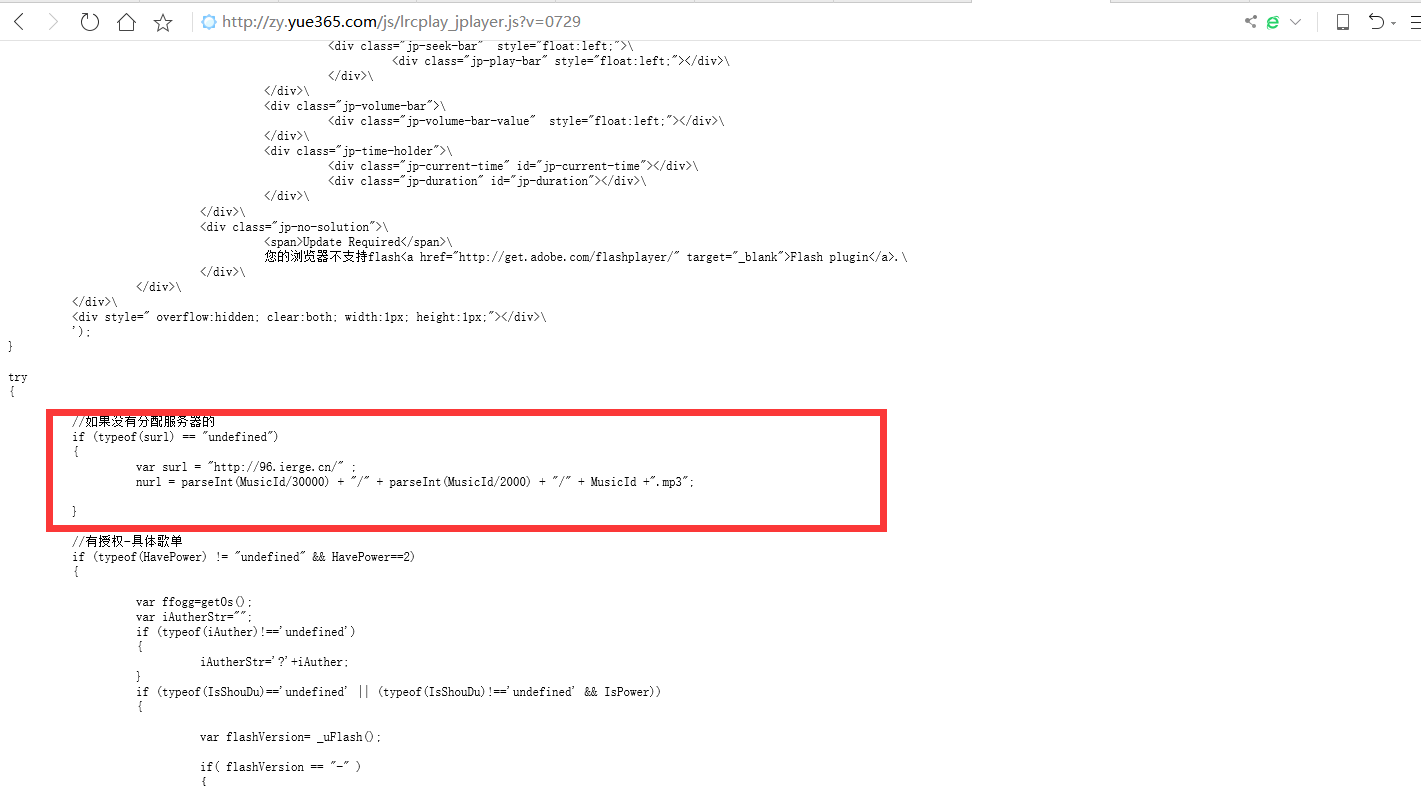
为了验证这个没有问题。我尝试本地写了一个HTML文档。来进行操作。
<script> var MusicId = "198372"; var surl = "http://96.ierge.cn/" ; nurl = parseInt(MusicId/30000) + "/" + parseInt(MusicId/2000) + "/" + MusicId +".mp3"; document.write(surl+nurl); </script> |
然后生产的URL直接放浏览器下载。发现可以下载。并正常播放。说明文件一切正常。
接下来我需要把首页中我喜欢的这个歌手的所有歌曲都下载下来。这个时候我第一时间想到的我的Python。
现在打开如下网站:红色标注处是我需要下载的音乐
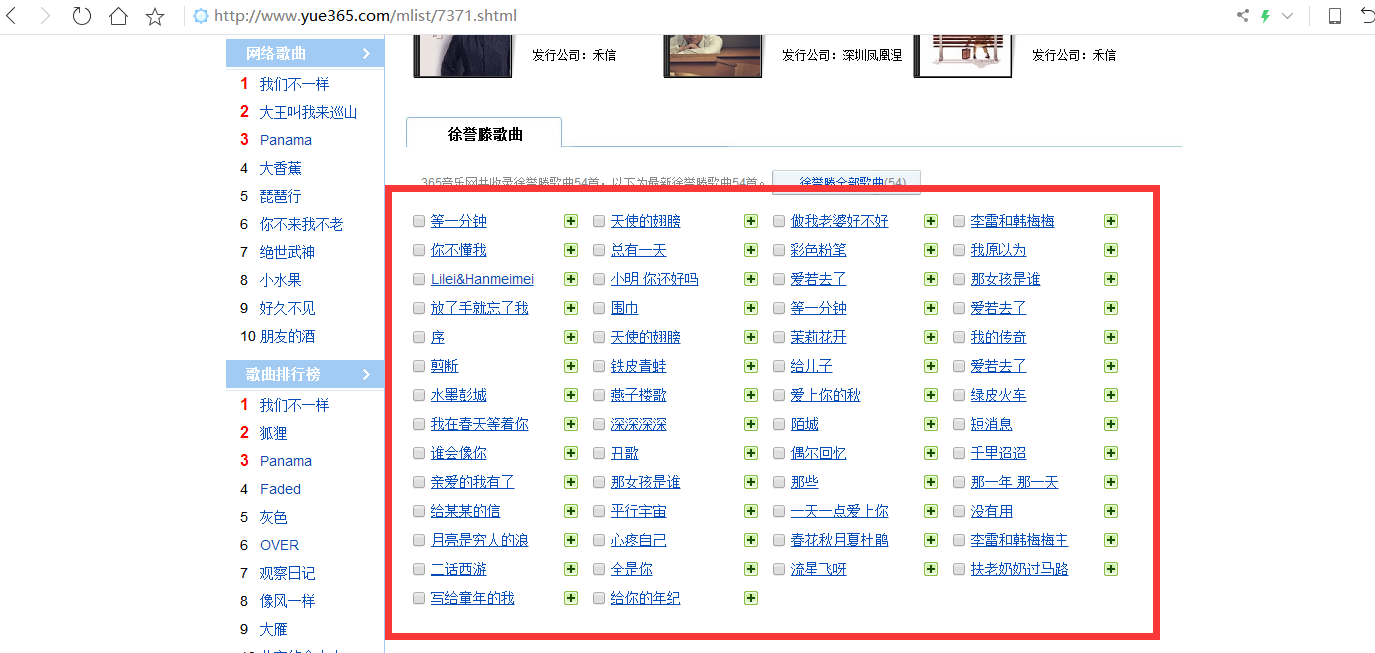
然后F12打开浏览器源码查看。将全文HTML源码拷贝到一个本地HTML文件中。文件名为music.html.红色标注处的地方是我们需要分析并获取所有歌曲的相应的musicid

接下来我上Pycharm。直接写代码。代码思路如下。先从HTML文件中获取相应音乐节点。然后分析获取每首音乐的musicid.同时需要获取音乐的歌名。
然后通过musicid构造音乐的真实地址。最后遍历下载即可。
下面将代码贴上:
#!/usr/bin/python
# _*_ coding:utf-8 _*_
# 音乐爬虫
if __name__ == "__main__":
import requests
from bs4 import BeautifulSoup
file = open("music.html","r")
html_doc = file.read()
soup = BeautifulSoup(html_doc, 'html.parser')
content1 = soup.find(id="content1")
li = content1.find_all("li")
#目标音乐站
url = "http://96.ierge.cn/"
musicid = []
musicname = []
musicurl = []
for x in li:
mtitle = x.a.get("title")
musicname.append(mtitle)
ids = x.input.get("title")
musicid.append(ids)
n1 = int(int(ids)/30000)
n2 = int(int(ids)/2000)
xurl = url + "/" + str(n1) + "/" + str(n2) + "/" + ids+".mp3"
musicurl.append(xurl)
print(xurl)
print(mtitle)
# url = 'http://96.ierge.cn/7/109/218490.mp3'
r = requests.get(xurl)
with open("music/"+mtitle+".mp3", "wb") as code:
code.write(r.content)
print(" 下载完成。。。。")
|
这里主要使用了两个包。一个requests包主要用于下载音乐。一个BeautifulSoup包来分析处理获取音乐ID及歌名。
整个下载过程也就几分钟就完成了。然后妥妥将音乐上传到云。下班回家可以在车上听音乐了。^_^