
系统环境: windows10
开发工具: pycharm5
先贴代码如下:
开发工具: pycharm5
先贴代码如下:
#!/usr/bin/pythyon
# _*_ coding:utf-8 _*_
# author: Robinn
import requests
import sys
result = ["松本行弘", "詹姆斯·高斯林", "林纳斯·托瓦兹", "方立勋"]
url = "http://www.baidu.com/s"
data = {
"wd": "java之父是谁?"
}
headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"};
response = requests.get(url=url, params=data, headers=headers)
response.encoding = "utf-8"
html = response.text
reload(sys)
sys.setdefaultencoding('utf8')
for i in range(len(result)):
result[i] = (html.count(result[i]),result[i],i)
result.sort(reverse=True)
print(data["wd"])
print("=============================================")
for x in result:
print(str(x[0])+" | "+x[1]+" | "+str(x[2]))
print("=============================================")
|
这个模块相当简单。这里介绍一下请求构造。
我们上工具Fiddler。然后用360浏览器模拟一个百度搜索。
找到百度请求URL。然后关键词wd.
然后直接用Fiddler获取一个请求头。构造请求头。
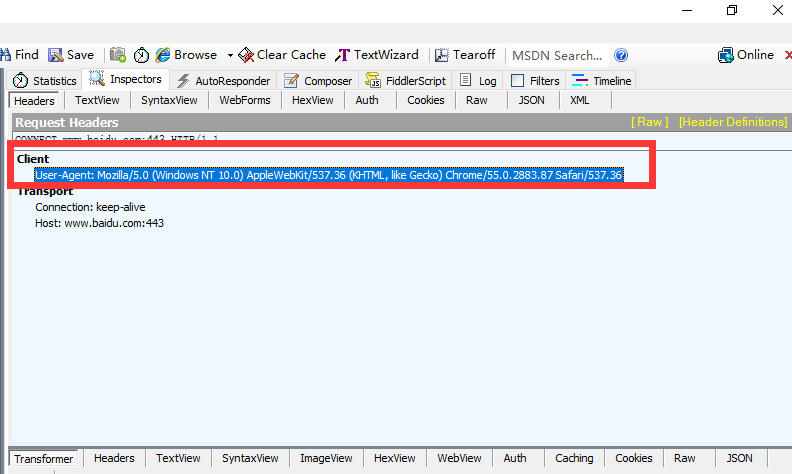
通过get方法直接获取HTML源码
然后我们把遍历答案列表。搜索HTML中答案出现的次数统计出来。生成一个新的元组。
将元组排序。排在第一个位置的元素就是我们的答案。
注: 这个算法其实还是有一点点误差的,不过我这我们忽略不计。主要介绍requests的使用。
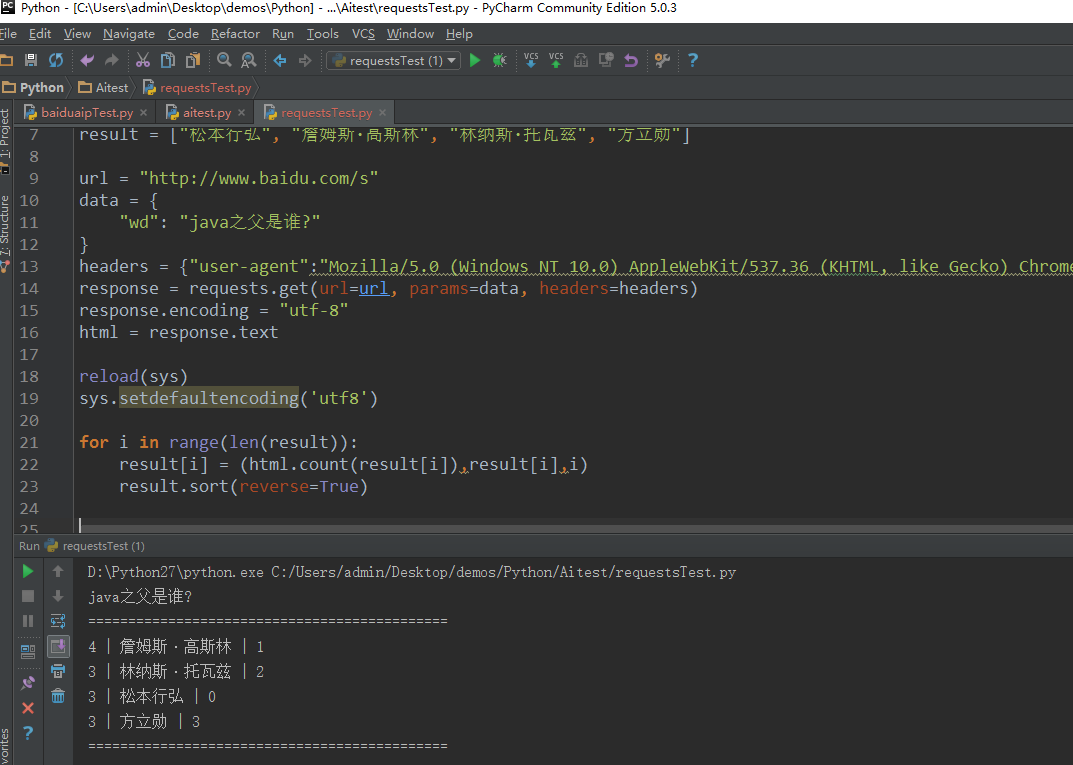
效果图示如下:
注:本文内容均系原创。如需转载分享请标明出处。
注:本文内容均系原创。如需转载分享请标明出处。