
我们在网上爬取信息时。经常由于访问频率问题导致被封IP。
IP被对方网站加入黑名单以后。我们的爬虫基本废了。
基于这种问题。我们需要建立自己的代理IP池。
首先。我们以爬取西刺代理为例。来爬取最新的代理IP。
完整代码如下:
完整代码如下:
#!usr/bin/python
# _*_ coding:utf-8 _*_
# author: Robinn
# 功能: 爬取西刺代理生成报表
import os
import sys
import time
import xlwt
import random
import requests
from goose import Goose
from bs4 import BeautifulSoup
MY_USER_AGENT = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
#构造headers USER_AGENT反爬
def getproxyip_list_useragent(urllist):
proxyurllist = []
for url in urllist:
#延时20秒爬取下一页
time.sleep(20)
#使用requests修改请求头Header
session = requests.Session()
agent = random.choice(MY_USER_AGENT)
headers = {"User-Agent": agent}
req = session.get(url, headers=headers)
soup = BeautifulSoup(req.text,"lxml")
proxy_list = soup.find_all("tr")
for proxyip in proxy_list:
iplist = []
all_td = proxyip.find_all("td")
if all_td:
for td_line in all_td:
val = td_line.text.strip()
if val:
iplist.append(val)
else:
if td_line.div:
iplist.append(td_line.div["title"])
else:
iplist.append(u"中国")
proxyurllist.append(iplist)
print(iplist)
print(url+"\n")
return proxyurllist
#从web地址获取内容
def getproxyip_list(urllist):
proxyurllist = []
for url in urllist:
time.sleep(10)
g = Goose()
article = g.extract(url=url)
soup = BeautifulSoup(article.raw_html,"html.parser")
proxy_list = soup.find_all("tr")
for proxyip in proxy_list:
iplist = []
all_td = proxyip.find_all("td")
if all_td:
for td_line in all_td:
val = td_line.text.strip()
if val:
iplist.append(val)
else:
if td_line.div:
iplist.append(td_line.div["title"])
else:
iplist.append(u"中国")
proxyurllist.append(iplist)
print(iplist)
return proxyurllist
#从文档内容获取
def getproxyip_list_htmlcontent(htmldoc):
proxyurllist = []
soup = BeautifulSoup(htmldoc,"lxml")
proxy_list = soup.find_all("tr")
for proxyip in proxy_list:
iplist = []
all_td = proxyip.find_all("td")
if all_td:
for td_line in all_td:
val = td_line.text.strip()
if val:
iplist.append(val)
else:
if td_line.div:
iplist.append(td_line.div["title"])
else:
iplist.append(u"中国")
proxyurllist.append(iplist)
return proxyurllist
def saveExcel(iplist):
#获取代理IP池所有结果
results = iplist
#设置Excel表头
fields = [u"国家",u"代理IP地址",u"端口",u"服务器地址",u"是否匿名",u"类型",u"速度",u"连接时间",u"存活时间",u"验证时间"]
#将表头字段写入到EXCEL新表的第一行
wbk = xlwt.Workbook()
sheet = wbk.add_sheet('ippool',cell_overwrite_ok=True)
for ifs in range(0,len(fields)):
field = fields[ifs]
sheet.write(0,ifs,field)
_col = sheet.col(ifs)
_col.width = 306*(int(ifs)+10)
ics=1
jcs=0
for ics in range(1,len(results)+1):
for jcs in range(0,len(fields)):
sheet.write(ics, jcs, results[ics-1][jcs])
type = sys.getfilesystemencoding()
print(u"代理IP池已经生成完毕,数据表正在打开,请稍等............")
wbk.save(u"proxyip.xls")
print(u"代理IP池数据表已经打开.数据文件保存在当前程序目录中,请查看程序所在目录...")
os.system(u"proxyip.xls")
if __name__ == "__main__":
# 爬取80页
# nn国内高匿
# nt国内普匿
pagenum = range(1,3)
pageList = []
for n in pagenum:
url = "http://www.xicidaili.com/nn/"+str(n)
pageList.append(url)
ippoollist = getproxyip_list_useragent(pageList)
saveExcel(ippoollist)
# with open("xiciip.txt","r") as f:
# htmldoc = f.read()
# ippoollist = getproxyip_list_htmlcontent(htmldoc)
# saveExcel(ippoollist)
|
代码解析:
首先获取IP可以从保存好的HTML文件中获取。也可以直接从网站上爬取(我这里主要选择从官方网站上获取)。
直接从网站上爬取本身这里要注意的问题是。同样西刺也做了访问频率限制。
这里我们可以伪装请求头Headers来构造。然后爬取一夜后我们延迟等待20秒钟。这样就可以顺利爬取了。
最后我们把获取的代理IP保存到Excel文件中即可。
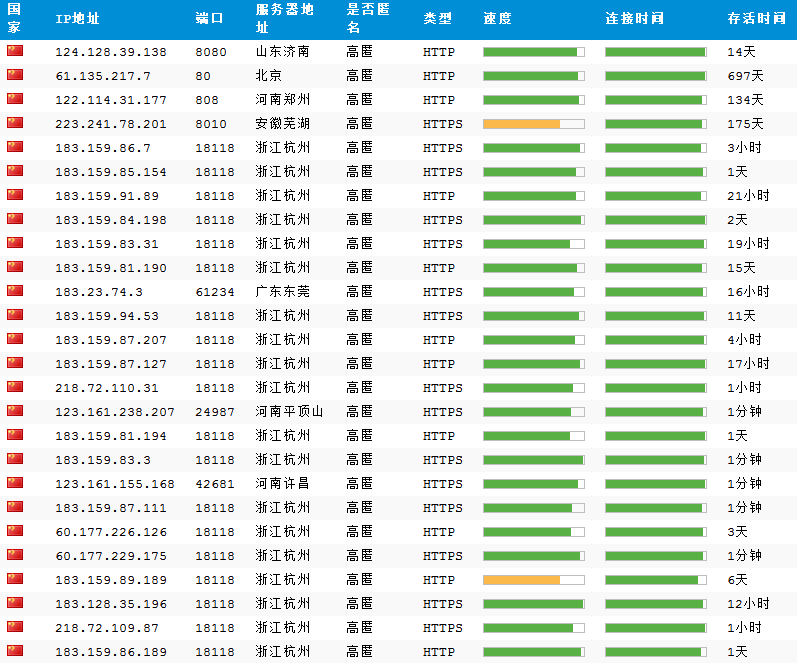
获取代理IP展示结果:
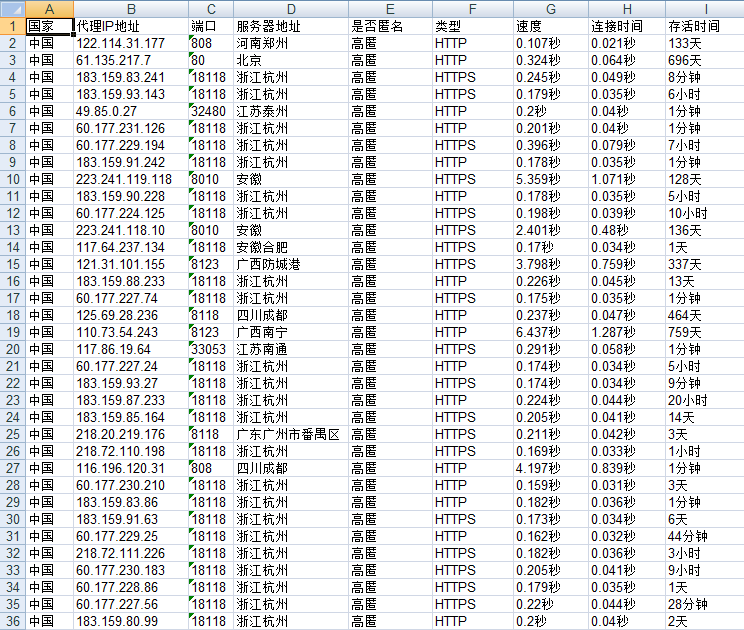
这里获取的代理IP后面我会用到。暂时就到这里。代码仅供参考。
获取代理IP展示结果:
这里获取的代理IP后面我会用到。暂时就到这里。代码仅供参考。