
最近关注快手上一个网友。想把他在小视频下载下来。
所以我决定使用Python相关技术来实现功能。(纯粹用于技术研究,请勿它用。)
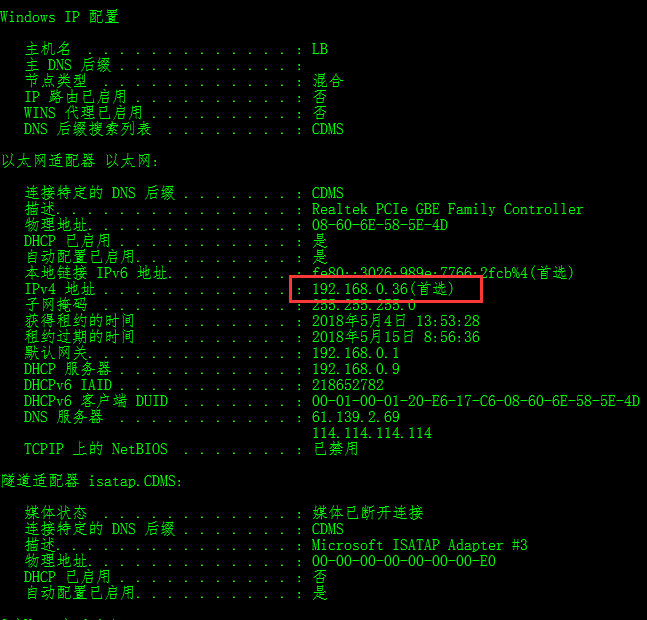
首先我们查询本机IP地址,使用命令ipconfig /all
如下图红色标注处:
然后我们配置Fiddler链接。
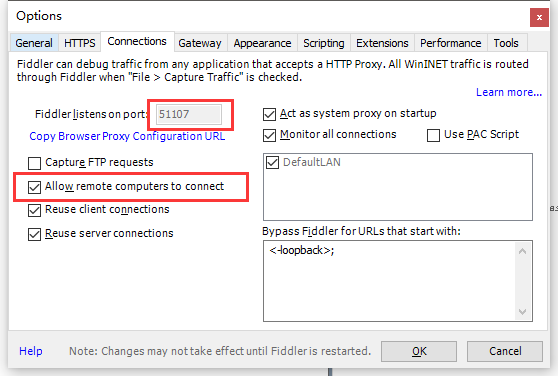
选择TOOLS-》Options-》Connections-》修改Fiddler listens on port:端口8888(我本机8888端口被占用。只能是其他端口:51116)
然后勾选下方:Allow remote computers to connect
如下图红色标注处:
然后我们手机连接到本机的wifi(确保手机和PC机保持在同一网络)
手机链接好PC机wifi后,我们开始配置Fiddler代理。
打开链接网络:选择修改网络-》点击IP,收入PC机本机IP:192.168.0.36 -》 输入端口号:51116 ,这里的端口号需要和Fiddler设置的端口号一致
确定设置好以后。
我们开始下载证书。
用手机打开浏览器访问:http://192.168.0.36:51116, 然后出现了一个英文页面:Fiddler Echo Service。
找到最底部后面的链接:【FiddlerRoot certificate】,点击后开始下载,下载完成后开始安装。
到这里我们已经完成了Fiddler抓包手机端HTTPS请求的解析配置。
下面我们抓包分析获取我们想要的数据。
当我们APP进入网友主页面时,抓包分析出请求URL。获取到一系列的QueryString.
完整URL:
http://api.ksapisrv.com/rest/n/feed/profile2?mod=HUAWEI(CUN-TL00)&lon=103.959309&country_code=cn&did=ANDROID_e0a15de49530bcd5&app=0&net=WIFI&oc=MYAPP&ud=938817008&c=MYAPP&sys=ANDROID_5.1&appver=5.6.3.6029&ftt=&language=zh-cn&iuid=DuAgO%2BT5sHeUL9lA%2BA8/roagbG2p/NbSiXj1JEIgvP/SctnqI6uEwnoH8DPtOxHI%2BPXdgIP2OR5mBguKrsiymTzw&lat=30.683821&ver=5.6&max_memory=128 |
同时我们获取到的POST数据如下:
'token': '9c90c6f0af5444c1834b509bd6b6c29b-938817008', 'user_id': "54090034732200", 'lang': 'zh', 'count': 30, 'privacy': 'public', '__NStokensig': 'ef702c97bf659d3e70f705a0a7da4792d4b697e212115f25babc03fa5afdf21d', 'referer': 'ks://profile/54090034732200/5962651320/1_i/1599422551105380352_h89/8', 'client_key': '3c2cd3f3', 'os': 'android', 'sig': '52187ae0be809b94f102c9ff17553a37' |
在这里我们看到sig和token,user_id,client_key等重要参数。这里我们不用管它。
user_id就是快手分配给每个用户的ID。这个ID是明文公开参数。
sig是快手根据user_id加上token,client_key等一系列时间戳参数然后生成了加密算法算出来的密文。这个具体什么算法这里不作深究。(注意:纯粹用于技术研究,请勿它用。)
通过请求获得了一个返回JSON的数据包。这个数据包包含了每个小视频的相关属性信息。比如标题,photo_id,视频URL等。
我们这里只需要视频的标题和视频的URL
现在我们开始用Python模拟APP实现获取网友视频的请求。然后解析返回的JSON,获取JSON包里面相应的数据。打包成LIST。最后做下载处理。
完整代码如下:
#!/usr/bin/python
# _*_coding:utf-8 _*_
import urllib2,urllib
import json
import re
if __name__ == "__main__":
url = "http://api.ksapisrv.com/rest/n/feed/profile2?mod=HUAWEI(CUN-TL00)&lon=103.959309&country_code=cn&did=ANDROID_e0a15de49530bcd5&app=0&net=WIFI&oc=MYAPP&ud=938817008&c=MYAPP&sys=ANDROID_5.1&appver=5.6.3.6029&ftt=&language=zh-cn&iuid=DuAgO%2BT5sHeUL9lA%2BA8/roagbG2p/NbSiXj1JEIgvP/SctnqI6uEwnoH8DPtOxHI%2BPXdgIP2OR5mBguKrsiymTzw&lat=30.683821&ver=5.6&max_memory=128"
data = {
'token': '9c90c6f0af5444c1834b509bd6b6c29b-938817008',
'user_id': "54090034732200",
'lang': 'zh',
'count': 30,
'privacy': 'public',
'__NStokensig': 'ef702c97bf659d3e70f705a0a7da4792d4b697e212115f25babc03fa5afdf21d',
'referer': 'ks://profile/54090034732200/5962651320/1_i/1599422551105380352_h89/8',
'client_key': '3c2cd3f3',
'os': 'android',
'sig': '52187ae0be809b94f102c9ff17553a37'
}
req = urllib2.Request(url)
req.add_header("User-Agent", "kwai-android")
req.add_header("Content-Type", "application/x-www-form-urlencoded")
params = urllib.urlencode(data)
try:
html = urllib2.urlopen(req, params).read()
except urllib2.URLError:
html = urllib2.urlopen(req, params).read()
result = json.loads(html)
#只匹配中文
reg = re.compile(u"[\u4e00-\u9fa5]+")
list=[]
for x in result['feeds']:
try:
title = x['caption'].replace("\n","")
name = " ".join(reg.findall(title))
name = name.strip().replace(' ','')
# video_q.put([name, x['photo_id'], x['main_mv_urls'][0]['url']])
list.append({"name":name,"photo_id":x['photo_id'],"url":x['main_mv_urls'][0]['url']})
except KeyError:
pass
#下载视频
for mv in list:
print(mv["url"],mv["photo_id"],mv["name"])
urllib.urlretrieve(mv["url"],'download/'+mv["name"]+"_"+str(mv["photo_id"])+'.mp4')
|
结果图如下:

以上代码主要实现了模拟APP来获取页面小视频。然后批量下来。
注: 此功能程序仅供技术研究和学习。请勿它用。